Practical Research Data Management
A clear way of organising and annotating your data helps re-use and understanding by others and by your future you. A practical way to organise data, scripts e.d. developed by Izel Erdogan.
README rules
Data folder readme Include metadata first:
Administrative metadata are data about a project or resource that are relevant for managing it; for example, project/ resource owner, principal investigator, project collaborators, funder, project period, etc. They are usually assigned to the data, before you collect or create them. Descriptive or citation metadata are data about a dataset or resource that allow people to discover and identify it; for example, authors, title, abstract, keywords, persistent identifier, related publications, etc. Structural metadata can be collection method, sampling procedure, sample size, categories, variables, etc. Structural metadata have to be gathered by the researchers according to best practice in their research community and will be published together with the data. Descriptive and structural metadata should be added continuously throughout the project. In the case of these details being stored elswhere attach the links and resources(possibly dynamic links) in the readme.
README content can be in this order:
Signature: Name, date created Downloaded on [date] by [name surname & email] from [paste the download link] Restrictions: if there are any restrictions mention it at the top with capital letters and include correspondence email to the data owner. e.g. ---RESTRICTIONS OF USE--- Resource: article identifier, website link, abstract of the article, correspondance Sample size, covariates/features of the dataset In the case of data collection by the person who created this readme: include structural metadata, or refer to a link where you have all the project documentation. Always note the samples that were taken out of the dataset with date, initials of whoever has performed it. Data analysis readme rules Overview of the steps taken in chronological order, possibly with script names. Creating scripts with numerically ordered prefixes (0_,1_,2_ etc.) already helps understanding this. Create symbolic links to the original data and softwares needed for the analysis. Log every change/creation of new files: filenames of the files that were created in the folder. If the code with which you created files are not in a script or a pipeline(for example if executed interactively) document the command in the readme. If it is a common data analysis folder, comment with your initials Possible passwords for zipped/encrypted folders If you ever delete data, mention with the reason(may not be necessary for troubleshooting intermediate data) Do not change the date, copy or move data with -p argument the keep the original date. In the case of data collection, describe all the variables, ancestry, Qquality control steps, filtration with rationale. When there is a newer version of the same dataset is released, create old folder containing all the data and related content to it. When formatting data for different softwares, create a folder for each software and keep the data separate. Describe the format changes with the code in the readme. In the case of using a web interfaced software for intermediate data include all the parameters that were chosen in software. When reformatting include the command used. (e.g. awk, sed, gsub or regex combinations). Often re-formatting is re-used, hence this saves a lot of time.
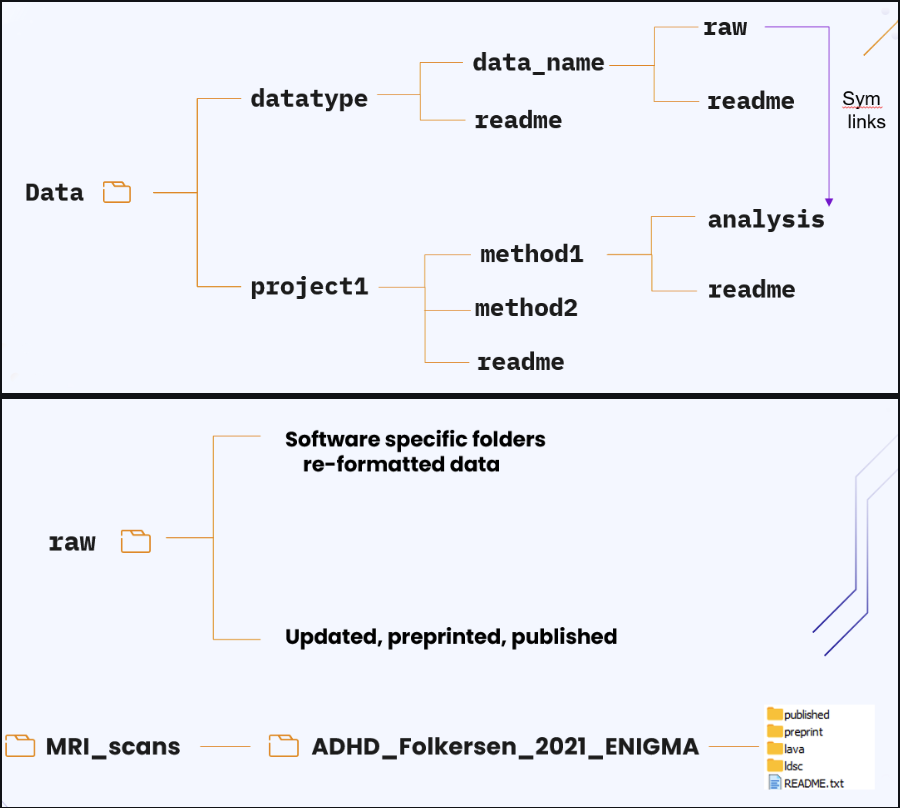
Folder structure
What is often suggested is project based structure. However in many cases the data you collected or downloaded will be used by more than that project or by others doing other projects in the group. A better approach is dataype based structure: for example summary statistics, This can co-exist with project_name based folders by the way. Meaning you dont have to have a datatype folder if that data is specific to that project. You can still have the project folder where you run your analyses and have your intermediate data, but this data will be used as a symbolic link to the actual data folder.
References: * Readme rules everyone can apply during data analysis on HPC (I. Erdogan)